고정 헤더 영역
상세 컨텐츠
본문
web crawler ( 웹 크롤러 )
인터넷에 있는 웹 페이지로 이동하여 데이터를 수집하는 프로그램
web page 구조를 이해하고
원하는 데이터를 가져오기
웹 크롤링의 과정
1. a- web site의 html접근
2. 크롤러를 이용하여 데이터 전송
3. 필요한 부분을 추출, 가공 후 저장
4. b- web site 의 html접근
requests
접근할 웹 페이지의 데이터를 요청/응답받기 위한 라이브러리
BeautifulSoup
응답받은 데이터 중 원하는 데이터를 추출하기 위한 라이브러리
_____________________________________________________________ import 방법
import requests as req
from bs4 import BeautifulSoup as bs
_____________________________________________________________
___________정리 ___________

_____________________________________________________________
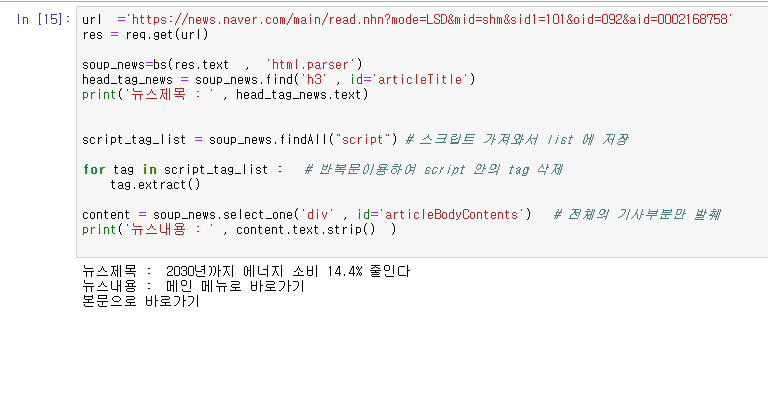
ex
뉴스 제목, 내용 가져오기









'1 a n G u a g e > PYTHON' 카테고리의 다른 글
| [PYTHON] &[Web Scraping] BeautifulSoup 사용법 (0) | 2019.08.25 |
|---|---|
| [PYTHON] &[machine learning] KNeighborsClassifier / LogisticRegression / LinearSVC 를 이용한 손글씨 분류 (0) | 2019.08.23 |
| [PYTHON] Pandas 개념정리 (0) | 2019.06.28 |
| [PYTHON] Numpy 개념 정리 (0) | 2019.06.27 |
| [PYTHON] for (0) | 2019.06.23 |





댓글 영역